
Tackling Chronic Kidney Disease: One Prognosis at A Time
In my previous article, “How AI is Changing the Game in Chronic Disease Care”, I explored the incredible ways that artificial intelligence (AI) is transforming the landscape of chronic disease care. I provided a level 100 overview of chronic diseases, the obstacles that come with them, and how AI is helping to overcome these challenges. This can give you a better understanding of how cutting-edge technology is shaping the future of healthcare, and how it can benefit patients suffering from chronic diseases.
In this post, I focus primarily on Chronic Kidney Disease (CKD), a ticking time bomb that has already exploded in India. With over 7.8 million people affected[1], it is an urgent public health crisis that requires immediate attention. The situation is dire as more than 1,75,000 new patients develop the end-stage renal disease (ESRD) each year, and the number is expected to increase by 10% annually[2]. And it is not just a nation-specific concern; according to the World Health Organization (WHO), CKD is now the 12th leading cause of death globally, and it is estimated that over 850 million people worldwide are living with this disease[3].

Risk Factors [4]
CKD not only affects patients and their families but also has a significant monetary impact on the world. The cost of treating ESRD is prohibitively expensive, contributing to a loss of productivity and a burden on the understaffed and overworked healthcare system.
In essence, the issue of CKD in India is not just a health issue, but a societal and economic one too. Fortunately, the use of data science and machine learning offers hope in the fight against CKD and can create a proactive strategy to combat CKD and prevent the worst-case scenarios. As Dr. Griffin Rodgers, the director of the National Institute of Diabetes and Digestive and Kidney Diseases (NIDDK), rightly said, “Chronic kidney disease is an under-recognized public health crisis that needs more attention and resources to prevent kidney failure and its complications.”
So, in this article, I delve deeper into how data science can play an important role in predicting and managing this disease Current solutions fail to manage diseases, so new approaches are needed. Using mathematical and statistical concepts, and predictive machine learning models. We can analyze demographic information, lab reports, and clinical data to make a difference in the lives of millions of people around the world.
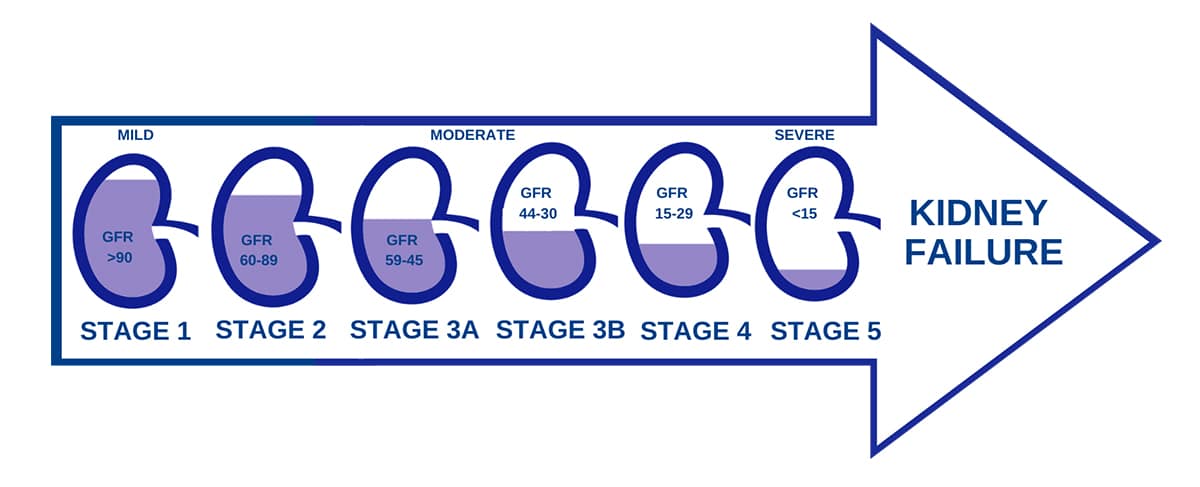
CKD has five stages - 1 to 5, the last stage being End-Stage Renal Disease (ESRD) or kidney failure, a point where it stops filtering the food you eat to get the nutrition required for your body.
A chronic disease progresses through time if a patient doesn’t change his/her lifestyle and, most importantly, if we don’t intervene early in the disease progression. So, how do we determine if one is in early stage of CKD? We use an estimate called eGFR (estimated glomerular filtration rate), which measures how well the kidneys are working or filtering. This eGFR is calculated based on various attributes such as demographic information, age, serum creatinine levels, etc.

Stages of CKD [5]
As depicted in the above image, eGFR values vary depending on the different stages of CKD. If the eGFR level is above 90, it signifies good kidney health, whereas if it falls below 15, it indicates kidney failure, necessitating immediate treatment or transplant. The detrimental aspect of CKD is its progressive nature, but the positive side is that we can halt its progression at any stage. To accomplish this, we must intervene early, modify the patient’s lifestyle, and deliver correct diagnosis, treatment, and education on CKD. Now that we understand CKD’s progression and how to prevent it from worsening, the crucial questions are how to intervene early and stop the disease from advancing to the later stages. The answer to these questions lies in proper management and data science! So how can we achieve this? Let’s explore a case I worked on, at Minfy, for an NGO that provides healthcare to CKD patients.
DISCLAIMER: The following work is solely intended for research purposes and should not be used by healthcare practitioners for diagnosing CKD. The machine learning models and data used in this article are simplified versions and not intended to reflect the full complexity of the actual models used.
Following, I discuss two important aspects of CKD diagnosis: early detection and predictive modeling.
Early Detection
Early detection in chronic disease care refers to identifying the presence of a disease or the risk of developing an infection at an early stage, before the onset of symptoms, or before the disease has progressed significantly[6].
As I explained in my previous article, early detection can be beneficial in
• Improving outcomes: It can lead to more effective treatment and management of CKD, which can improve outcomes for patients. For example, if a patient with diabetes is diagnosed early on, he/she can take steps to control blood sugar levels and prevent the development of complications.
• Reducing costs: It can reduce the costs associated with CKD, as treatments and management strategies are more effective when they are initiated early on.
• Better access to care: It can improve access to care for patients, as they are more likely to be diagnosed and treated before the disease progresses and becomes more difficult to manage.
• Reducing the burden on healthcare systems: It can also help reduce the burden on healthcare systems, as patients with CKD diagnosed early on are less likely to require hospitalization or other intensive care.
• Improving the quality of life: It can improve the quality of life for patients, as they can take steps to manage their disease and prevent complications before they occur.
To identify chronic kidney disease (CKD) at an early stage, it is important to monitor various factors such as the individual’s eGFR level, age, lifestyle, and other relevant indicators. Once this information has been gathered, machine-learning techniques can be utilized to aid in the detection process.
To train the machine learning model, I plan to utilize the University of California Irvine’s web data repository on Chronic Kidney Disease [7]. This dataset includes approximately 400 data points, consisting of 11 numeric and 14 nominal features, as well as a binary classification of CKD and NOTCKD. Of the 400 data points, 150 are classified as NOTCKD (healthy), while the remaining 250 are classified as CKD (unhealthy).
Given the limited number of data points available (~400), I plan to use CTGAN, a generative adversarial network (GAN)-based approach for modeling tabular data distribution and generating additional data points. By utilizing the latent space distribution of the original data, I aim to generate approximately 50,000 additional observations.
Following code snippet shows the complete procedure for generating synthetic data from a seed value and saving it in a CSV file for future use.
Synthetic Data Generation



The distributions of the original data vs synthetic data
It is apparent that the distribution of the generated data is comparable to that of the original data, and therefore, it can be safely used for training the machine learning model.
Model Training and Evaluation


The results of data analysis and model evaluation are shown below.

Scatter plot of a few continuous variables v/s target

Pair-wise scatter plot of a few continuous variables

Heatmap of a few continuous variables for the target
Accuracy of XGBoost Classifier

Confusion Matrix Plot

The preceding procedure can be utilized to train a machine learning model to identify individuals who have CKD at an early stage. The tool helps to detect signs of disease quickly and easily by taking into account only a small number of factors, such as those found in routine lab tests, urine tests, and basic personal data.
Predictive modeling
Predictive modeling in CKD care can be used to identify individuals at high risk of developing CKD and predict outcomes through analyzing data such as electronic health records.
• Identifying high-risk patients: Machine learning algorithms can be trained on large amounts of data, such as patient EHRs, to identify patterns and predict outcomes.
• Predicting progression: Predictive modeling can be used to predict the progression of CKD such as diabetes by analyzing data such as blood glucose levels and medication
To develop a predictive machine learning model for CKD progression, it is necessary to have longitudinal patient data capturing disease progression through the five CKD stages. Mathematical models have been employed for the initial classification of patients into these stages, followed by machine learning modeling to develop the predictive model.
Let’s build a predictive model using the XGBoost classifier to predict the stages of CKD using a synthetic dataset.
Limitation: This method has certain limitations. Specifically, due to the unavailability of labeled data for each stage, a mathematical model formula was utilized to create a new column in the dataset representing the CKD stage. However, it must be acknowledged that obtaining labeled data from healthcare professionals would be a more robust and reliable approach. Thus, the current limitation presents an opportunity to further improve the methodology through enhanced data collection methods.




Accuracy of XGBoost Multi-Class Classifier

Confusion Matrix Plot
Chronic Kidney Disease (CKD) is a global public health issue that demands immediate attention. Treating End-Stage Renal Disease (ESRD) is financially prohibitive, burdening an already stretched healthcare system. But hope lies in data science and machine learning, offering a proactive strategy to combat CKD and prevent its worst-case scenarios.
Early detection is crucial in managing and preventing CKD. Predictive machine learning models, using advanced mathematical and statistical concepts, can help doctors intervene early, change patients’ lifestyles, and stop CKD progression. Leveraging these cutting-edge technologies can lead to improved patient outcomes, reduced healthcare costs, and a healthier society. Proactive intervention, tailored treatments, and early detection are the keys to success in chronic disease management. Let’s work together to harness the power of data science to make this vision a reality.
LIFESPAN – The Healthcare Management System
As mentioned earlier, forecasting the progression of Chronic Kidney Disease poses a challenge due to the limited availability of longitudinal data. Nonetheless, this obstacle can be overcome with appropriate techniques and sufficient resources. It is imperative to acknowledge the complexity of the task, but with careful planning, comprehensive data collection, and the utilization of advanced modeling techniques, we can successfully predict CKD advancement and provide valuable insights for both medical professionals and patients. The main question, therefore, is how we can obtain the required longitudinal data.
Introducing the revolutionary new product from Minfy — LifeSpan!
LifeSpan can collect vital health data on numerous attributes, not just limited to CKD but any existing disease. With LifeSpan, you can streamline the way health data is collected and managed — from hospital administration to digital records, eliminating the tedious paper trail and saving valuable time. Say goodbye to cumbersome paperwork and hello to a future where data is easily accessible, and compliance is effortlessly tracked. Be ready to experience the future of health data collection with LifeSpan.
— Author: Gaurav Lohkna
References
[4] Image: https://www.siemens-healthineers.com/en-in/news/chronic-kidney-disease.html
[5] Image: https://www.dneph.com/wp-content/uploads/2020/01/Stages-of-CKD-Arrow-Diagram-Only-2.jpg
[6] https://medium.com/nerd-for-tech/how-ai-is-changing-the-game-in-chronic-disease-care-d4ca145a7f49
[7] Data: https://archive.ics.uci.edu/ml/datasets/chronic_kidney_disease



.jpg)

{kind=link}