
Last year’s EGIRA post set the north star: a reference architecture that ties together data harmonization, context-aware connectors, orchestration, and guardrails so enterprise intelligence can actually run in the real world—not just in demos. The natural follow-up question we kept hearing after that piece was: “So—what does this look like when you actually ship something?” That’s where DataTalk comes in. DataTalk is one of the first “real” EGIRA implementations because it tackles the most universal enterprise constraint: disciplined data access—getting from a business question to a governed, auditable answer across messy, multi-system reality.
And that’s why this prelude is necessary. Without it, DataTalk can get misunderstood as “just another chat-with-your-data UI.” The prelude makes the point that DataTalk is not a standalone feature—it’s a deliberate expression of EGIRA’s core principles: staged orchestration (intent → composition → execution → presentation), embedded governance (RBAC/ABAC, masking, audit), and working across heterogeneous sources without pretending the enterprise is clean and centralized. In other words, the prelude is the bridge that turns our message into: “EGIRA was the vision. DataTalk is the first proof it works under production constraints.”

Your Data Stack Is Fine. Your Answers Are Slow.
Why the real enterprise bottleneck is not storage, dashboards, or AI fluency. It is data access.
If your organization has a data warehouse and still waits days for answers, the warehouse is not the problem.
Access is.
That is the quiet contradiction inside many otherwise mature data organizations. The business has invested in storage, pipelines, dashboards, analytics teams, and increasingly, AI. And yet a simple question can still take too long to answer.
Why is churn rising in one segment? Which deals are stalling this week? Where are fulfillment delays getting worse?
The answer usually exists. But it is scattered across systems, buried in schemas, restricted by permissions, and slowed down by the human process required to retrieve it safely.
By the time the request is translated, routed, queried, validated, and turned back into something a business stakeholder can use, the moment has passed.
That is the problem DataTalk is designed to solve.
DataTalk is an enterprise-grade natural language interface for governed data access across heterogeneous systems. It allows business users to ask questions in plain English, translates those questions into controlled queries across the sources they are authorized to use, and returns answers in a form they can act on. It is best understood not as a replacement for the analytics stack, but as the missing access layer between enterprise data infrastructure and everyday decision-making.
The Last-Mile Problem in Enterprise Data
Most enterprises do not have a data shortage problem. They have a last-mile access problem.
The data may already live in warehouses, operational databases, SaaS systems, APIs, and graph stores. The technical estate is often rich. The issue is that most people who need answers are not the same people who know how to navigate that estate.
So the organization creates a familiar workaround:
- A business user asks a question.
- An analyst or data engineer interprets it.
- Someone identifies the right source systems.
- Someone checks permissions and sensitive fields.
- Someone writes or validates the query.
- Someone translates the result back into a business answer.
That workflow may be manageable once or twice. At scale, it becomes a drag on decision-making.
It also creates a subtle cultural problem: data exists, but access to insight still depends on technical mediation.
Where Traditional BI Stops Short
Traditional BI tools solved an important problem. They made structured reporting, dashboards, and recurring metrics far more accessible than they used to be.
But they did not eliminate the long tail of business questions.
They did not remove the need to understand where data lives. They did not eliminate the need for curation. They did not solve cross-system ad hoc questions. And they did not make every non-technical stakeholder comfortable enough to explore data on their own.
This is why so many teams still end up asking for “one more dashboard,” “one more filter,” or “one quick report.”
The issue is not that BI failed. The issue is that BI was never meant to be the entire answer to enterprise data access.
Why Generic AI Is Not Enough
The next wave of tools tried to close this gap with conversational interfaces. On the surface, that makes sense. If people can ask questions in natural language, surely access gets easier.
But in the enterprise, a prompt box is not the hard part.
The hard part is everything around the prompt:
- Which systems should be queried?
- What is this user allowed to access?
- Which fields need masking?
- What policies have to be enforced?
- What gets logged for audit and compliance?
- What happens when the answer spans multiple sources?
This is where many “chat with your data” experiences break down. They can sound intelligent without solving the operational constraints that decide whether a product is actually deployable.
Enterprise data access is not just a language problem. It is a connectivity problem, a permissions problem, a validation problem, and a governance problem.
What DataTalk Is
DataTalk is not trying to make enterprise data feel novel. It is trying to make it usable.
That is an important distinction. The goal is not conversation for its own sake. The goal is to reduce the friction between a business question and a governed answer without forcing every request through a technical intermediary.
DataTalk is not trying to replace every dashboard, data model, or analytics workflow. It is designed to solve a narrower and more persistent problem: helping organizations move from business question to governed answer with much less friction.


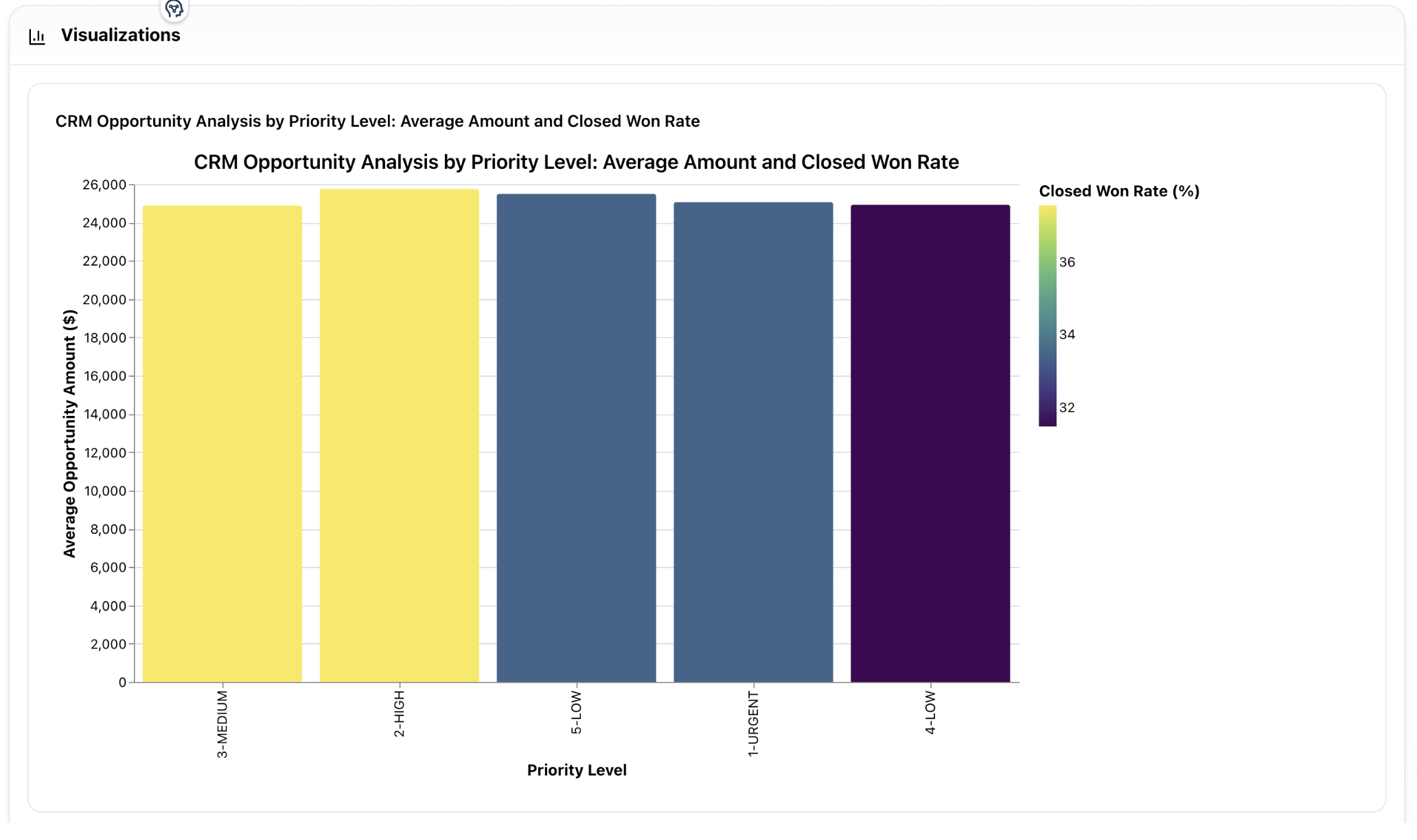
Where DataTalk Fits Best
DataTalk is strongest in organizations where data is already strategically important, but still too hard to access in the flow of work.
That usually means a few things are true at the same time:
- Data is spread across multiple systems, not one tidy reporting layer.
- Business teams ask frequent ad hoc questions that do not justify a new dashboard every time.
- Analysts are overloaded with repetitive, interrupt-driven requests.
- Security and compliance teams will not allow unmanaged AI access to production data.
- The organization wants faster self-service without a disruptive rip-and-replace analytics program.
This is where DataTalk fits best: not as a prettier dashboard, and not as a generic AI assistant, but as an operational layer between enterprise data and the people who need answers.
It is a weaker fit when:
- A single system already answers most questions through existing dashboards.
- The primary requirement is advanced dashboard authoring or highly customized BI presentation.
The Value Proposition, Without the Hype
The value of DataTalk is not “AI for analytics.” That phrase is too broad to be useful.
The real value is more practical: DataTalk reduces the friction between business questions and governed answers.
When that friction goes down, several things improve at once.
Business users get faster access to information. Analysts recover time otherwise spent on repetitive one-off requests. IT avoids becoming the permanent routing layer between systems and stakeholders. Security leaders get a controlled alternative to shadow AI usage. Executives get a more responsive operating model without waiting on reporting backlogs.
DataTalk does not just make querying easier. It changes who can safely participate in decision-making.
Who Feels the Value First
The obvious audience is business users. They benefit because they no longer need to know SQL, remember where data lives, or wait for a specialist to mediate every question.
But the value chain is broader than that.
Analysts benefit because repetitive low-leverage requests stop consuming so much of their day.
Enterprise architects and IT teams benefit because they get a system that can work across a heterogeneous environment without turning into another brittle integration project.
Security and compliance teams benefit because governed access, masking, and auditability are part of the product posture, not an afterthought.
This matters because enterprise software is rarely adopted by end users alone. Products succeed when business stakeholders, technical teams, and governance owners can all say yes for different reasons.
Common Objections, Answered Honestly
“We already have BI tools.”
That is normal. Most mature organizations do.
DataTalk is not primarily a replacement for dashboards or recurring reporting. It is designed for the long tail of questions that do not already have a dashboard and should not require a sprint to answer. In practice, it often complements BI by reducing the pressure to build one more report for every new question.
“Why not just use a general-purpose LLM?”
Because the prompt is not the product.
Generic chat tools can sound smart while remaining operationally unsafe. Enterprise data access depends on controlled retrieval, source awareness, permissions, validation, masking, and auditability. DataTalk is built around those requirements.
“Our environment is too messy for this.”
Messy environments are the point.
If all your data lived in one perfectly modeled system and every important question already had a dashboard, you would not need DataTalk. The value appears when real enterprise complexity gets in the way of timely answers.
“Business users will not trust AI answers.”
They should not trust a black box.
Trust comes from governed behavior, grounded outputs, visible controls, and predictable policy enforcement. Adoption is not created by clever phrasing. It is created by confidence in how the system behaves.
“If it is easy to use, it probably is not enterprise-grade.”
This is one of the stranger assumptions in enterprise software.
Ease of use is not evidence of weakness. In well-designed systems, simplicity is the result of complexity being handled in the right place: inside the product, not pushed onto the user.
The Real Positioning
DataTalk is a governed conversational data access layer for enterprises that need faster answers across complex data environments.
That positioning matters because it avoids two common mistakes.
The first is overselling DataTalk as a total replacement for the analytics stack. The second is underselling it as just another chat interface.
It is neither.
It is the missing layer between enterprise data infrastructure and everyday business decision-making.
The Takeaway
Enterprise data is not slow because companies lack storage, dashboards, or AI tools.
It is slow because access is still too technical, too fragmented, and too dependent on human mediation.
That is the last-mile problem.
DataTalk exists to close it.
If your organization already has the data, but still struggles to turn simple business questions into timely, governed answers, that is where DataTalk earns its place.







